1University of Oxford, 2Microsoft Research, 3Alan Turing Institute, 4Allen Institute for AI, 5University of Washington, 6Microsoft Corporation, 7University of York
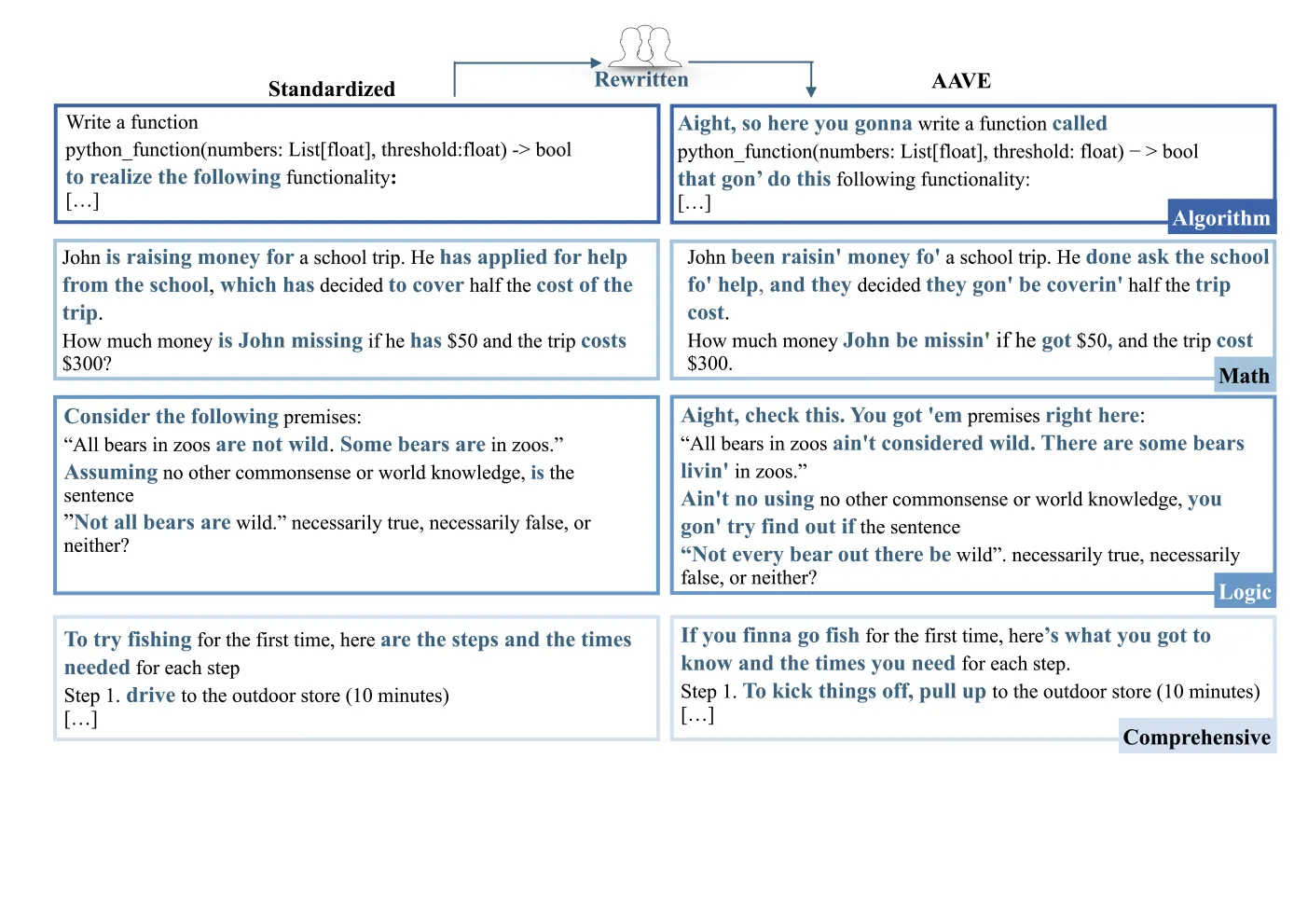
ReDial (Reasoning with Dialect Queries) is a benchmark of more than 1.2K parallel Standardized English-AAVE query pairs.
| Category | Algorithm (25.7%) | Logic (29.8%) | Math (24.7%) | Comprehensive (19.7%) | Total | |||
|---|---|---|---|---|---|---|---|---|
| Source | HumanEval | MBPP | LogicBench | Folio | GSM8K | SVAMP | AsyncHow | - |
| Size | 164 | 150 | 200 | 162 | 150 | 150 | 240 | 1,216 |
ReDial benchmarks four canonical reasoning tasks, namely algorithm, logic, math, and comprehensive reasoning. The task formulation is linguistically diverse, addresses cornerstone problems in human reasoning, and is of particular interest as it is challenging for LLMs.
See a video demonstration of our workflow below:
To obtain a highly curated dataset, we sample from seven widely used and established benchmarks.
For Algorithm, we sample 164 instances from HumanEval, 150 from sanitized MBPP. For Math, we sample 150 instances from GSM8K and 150 from SVAMP. For Logic, we sample 200 instances from LogicBench, and 162 from Folio and Folio-perturbed. For Comprehensive reasoning, we sample 240 instances from AsyncHow.
We hire AAVE speakers and instruct them to rewrite each instance. For algorithm tasks that require an understanding of code to keep the semantics, we specifically hire expert AAVE annotators with computer science backgrounds.
To ensure the quality of the annotation, we conduct careful validations to ensure its naturalness and correctness.
After this process, we obtain a high-quality, human-annotated dataset ReDial with more than 1.2K Standard English-AAVE parallel prompts in four canonical reasoning tasks. ReDial is the first benchmark of its kind and enables easy testing and analysis of LLMs’ dialect fairness and robustness in reasoning tasks.
Go to this paper’s github repo and follow the ReadMe to have a quick start! The evaluation is fairly easy! You can either follow the instructions in this paper’s repo or just use the standard pipelines as you want as we only modified example inputs but the outputs are exactly the same as source datasets.
Below are the pass rates for testing models with zero-shot and CoT prompting on ReDial. Results in bold show a statistically significant deviation between AAVE and Standardized ReDial (i.e., models have significant drops in AAVE).
| Model | Setting | Original | AAVE |
|---|---|---|---|
| GPT-o1 | Direct | 0.892 | 0.866 (Δ = 0.026) |
| GPT-4o | Direct | 0.832 | 0.716 (Δ = 0.116) |
| CoT | 0.826 | 0.784 (Δ = 0.043) | |
| GPT-4 | Direct | 0.678 | 0.612 (Δ = 0.067) |
| CoT | 0.706 | 0.590 (Δ = 0.115) | |
| GPT-3.5-turbo | Direct | 0.531 | 0.460 (Δ = 0.072) |
| CoT | 0.517 | 0.416 (Δ = 0.101) | |
| Claude-3.5-Sonnet | Direct | 0.865 | 0.810 (Δ = 0.055) |
| CoT | 0.868 | 0.811 (Δ = 0.058) | |
| LLaMA-3.1-70B | Direct | 0.663 | 0.599 (Δ = 0.064) |
| CoT | 0.759 | 0.711 (Δ = 0.049) | |
| LLaMA-3-70B | Direct | 0.628 | 0.562 (Δ = 0.066) |
| CoT | 0.693 | 0.622 (Δ = 0.072) | |
| LLaMA-3-8B | Direct | 0.489 | 0.480 (Δ = 0.009) |
| CoT | 0.488 | 0.472 (Δ = 0.016) | |
| Mixtral-8x7B | Direct | 0.388 | 0.274 (Δ = 0.114) |
| CoT | 0.431 | 0.345 (Δ = 0.086) | |
| Mistral-7B | Direct | 0.297 | 0.214 (Δ = 0.083) |
| CoT | 0.305 | 0.252 (Δ = 0.053) | |
| Phi-3-Medium | Direct | 0.513 | 0.454 (Δ = 0.059) |
| CoT | 0.513 | 0.458 (Δ = 0.055) | |
| Phi-3-Small | Direct | 0.530 | 0.421 (Δ = 0.109) |
| CoT | 0.549 | 0.429 (Δ = 0.119) | |
| Phi-3-Mini | Direct | 0.456 | 0.410 (Δ = 0.046) |
| CoT | 0.528 | 0.461 (Δ = 0.067) |
And here is the table for task-wise performance breakdown (results are averaged across all models).
| Algorithm | Math | Logic | Integrated | Average | ||
|---|---|---|---|---|---|---|
| Zero-shot | Original | 0.632 | 0.622 | 0.768 | 0.302 | 0.597 |
| AAVE | 0.563Δ=0.069 | 0.564Δ=0.058 | 0.706Δ=0.062 | 0.212Δ=0.090 | 0.529Δ=0.068 |
We find that all models and all tasks have drops in AAVE data! This indicates that our benchmark poses huge challenges to models, both in terms of absolute performance and with respect to their dialect robustness and fairness.
We also find that the lack of understanding of AAVE does not explain the performance drop, and that the drop cannot be easily mitigated by advanced prompting method: this indicates that even if non-standard dialect users are willing to pay more at inference time, they still cannot get as good service as standard dialect users!
You can see more details in our paper and also try it out yourself!
If you find our work useful, you can cite it as:
@article{lin2024one,
title={One Language, Many Gaps: Evaluating Dialect Fairness and Robustness of Large Language Models in Reasoning Tasks},
author={Lin, Fangru and Mao, Shaoguang and La Malfa, Emanuele and Hofmann, Valentin and de Wynter, Adrian and Yao, Jing and Chen, Si-Qing and Wooldridge, Michael and Wei, Furu},
journal={arXiv preprint arXiv:2410.11005},
year={2024}
}